

片头废话:
本教程将教你如何让你自己部署的小智AI服务端使用IndexTTS语音合成模型适配器,开始前请确保你已经部署了小智AI服务端,若没有部署过小智AI服务端的,请看我的这个视频:
注意事项:
由于目前TTS合成适配器还在测试中,所以暂时不会公开下载Index TTS适配器文件,我会在发布Index TTS适配器视频教程后,公开Index TTS适配器的下载地址
第一步,下载Index TTS整合包
整合包来自网络,如有侵权请联系我删除,谢谢!
夸克网盘:https://pan.quark.cn/s/5aff019931ff
QQ群 群文件下载(点击群号可跳转加群):
一群:621457510
二群:1031065631
三群:195260107
下载好后将其解压,解压后放在一旁备用
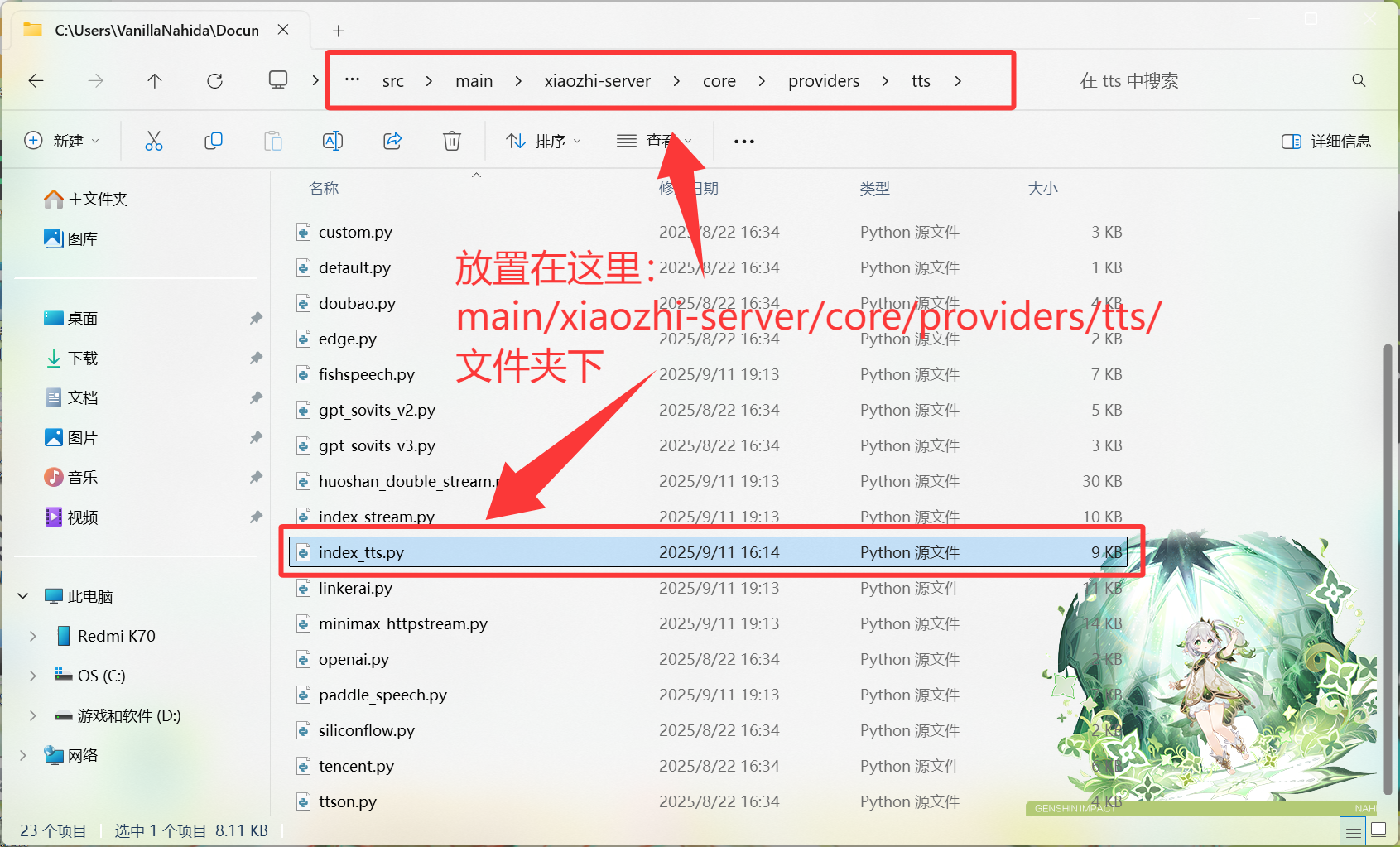
第二步,下载TTS适配器文件
请在Q群内下载好TTS适配器文件,下载好后的文件一般是名为 index_tts.py 的py文件
下载好后,请将其放在如下目录:main/xiaozhi-server/core/providers/tts
第三步,在配置文件里增加Index TTS的配置项,并启用Index TTS
打开 .config.yaml ,在里面找到这个配置项:
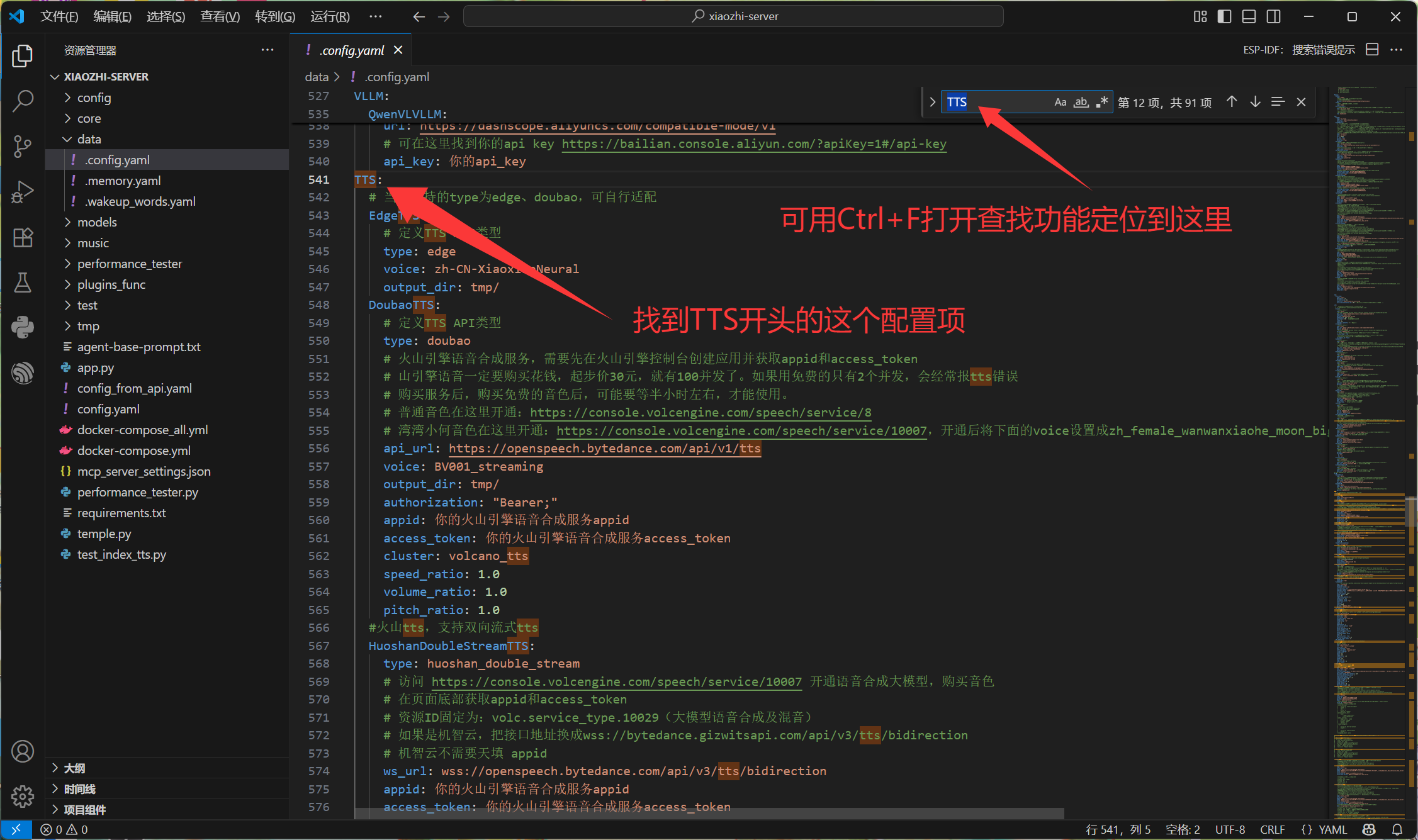
在此处粘贴如下配置项:(注意缩进!注意缩进!注意缩进!)
这里需要修改reference_audio_path 参考音频路径为你准备的参考音频的绝对路径
IndexTTS:
# 定义TTS API类型 index_tts
# 需要先启动index_tts服务
# 常规设置
# url: IndexTTS 默认API地址
# reference_audio_path: 参考音频路径,必选
# infer_mode: 推理模式,分为普通推理和批次推理,长文本建议使用批次推理
# 以下是高级设置,不懂就不要乱改,除非你完全知道你在改什么
# 以下是分句设置,参数会影响到音频质量和生成速度
# max_text_tokens_per_sentence: 分句最大Token数,建议80~200之间,值越大,分句越长;值越小,分句越碎;过小过大都可能导致音频质量不高
# sentences_bucket_max_size: 分句分桶的最大容量(批次推理生效),建议2-8之间,值越大,一批次推理包含的分句数越多,过大可能导致内存溢出
# 其他的详见IndexTTS文档
type: index_tts
url: "http://127.0.0.1:7860/"
output_dir: tmp/
reference_audio_path: "C:/Users/VanillaNahida/Music/纳西妲语音数据集/常规语音 - Normal/是我刚才抽空制造的小东西,你可以理解为升级版的虚空终端。.wav"
infer_mode: "批次推理"
max_text_tokens_per_sentence: 120
sentences_bucket_max_size: 4
do_sample: true
top_p: 0.8
top_k: 30
temperature: 1
length_penalty: 0
num_beams: 3
repetition_penalty: 10
max_mel_tokens: 600修改后的配置文件如图所示:(注意缩进!注意缩进!注意缩进!)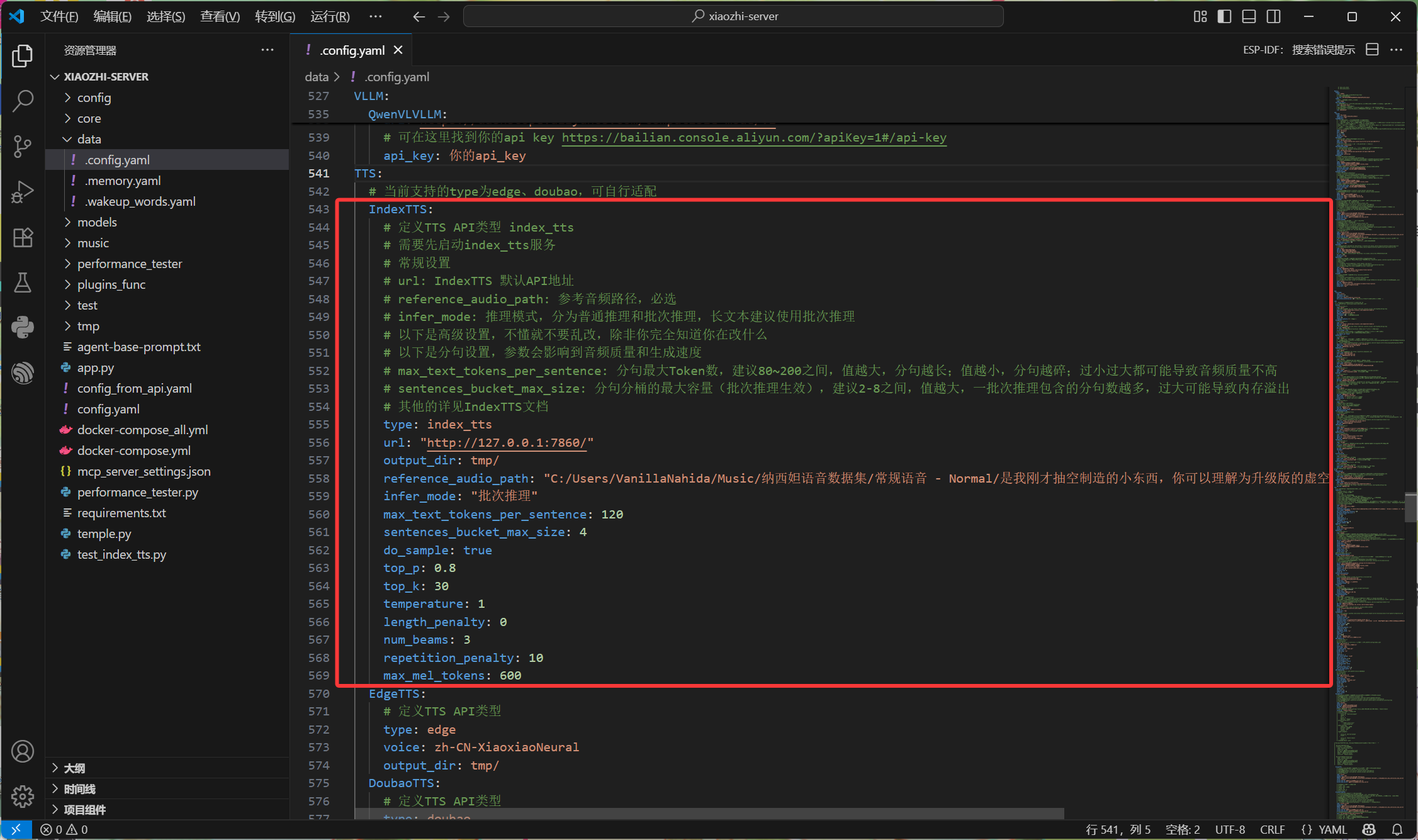
在配置文件中找到这个配置项,并将其改为IndexTTS,改好后保存文件,如图所示: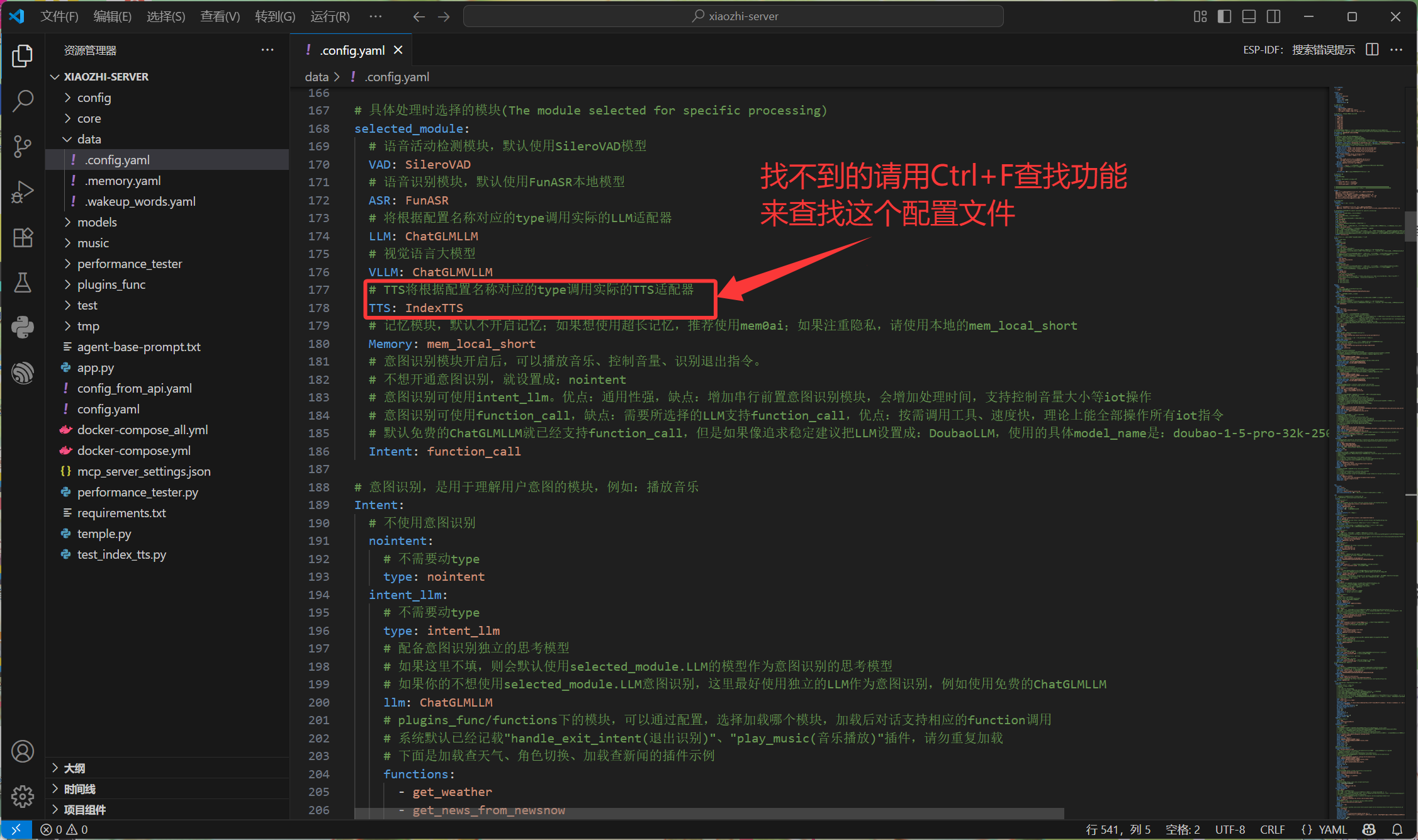
这样就是已经成功的启用了 Index TTS 适配器了
第四步,启动Index TTS整合包
运行 启动程序.bat 即可启动IndexTTS服务
期间可能会打开浏览器,忽略即可
第五步,启动小智AI服务端
现在你就可以愉快的使用IndexTTS了~
小智AI服务端使用IndexTTS适配器合成语音教程
https://www.xcnahida.cn/?p=ey8AUxey
评论